
안녕하세요, Soa입니다!
٩(ˊᗜˋ*)و
아직도 중간고사가 안 끝났는데...! (망ㅎㅏㄹ)
이제 겨울인 것 같아요... 너무 추워.....ㅠ....(더위랑 추위 둘 다 타는 개복치)
시험 따위는 잊고 ^^
함께 데이터 분석을 해봅시다!!!!
저번 포스팅에서는 데이터 수집 중에, 유료 데이터 활용 범위 때문에
문의를 남겨 놓고 이후에 데이터 사용 여부를 결정하기로 하고 끝냈었는데요!
[다음 썸트렌드 유료 플랜, 유료 데이터 활용 범위]
다음 썸트렌드에 1:1 문의를 한 결과, 답이 왔습니당!!!

출처를 밝히기만 하면 유료 데이터 또한 활용에는 법적 문제가 존재하지 않다는 답변이 왔습니다!
다음 썸트렌드의 유료 플랜을 구매한 경우,
출처를 밝힌다면 SNS 활용에는 법적인 문제가 없습니다.
혹시라도 다음 썸트렌드에서 유료 데이터의 활용 범위에 대해서 궁금하셨던 분들이 계시다면
이 답변을 참고하시면 좋을 것 같습니다!
그래서 다음 썸트렌드 데이터는 유료 플랜을 구매해서 사용하기로 했습니다,,, 피 같은 돈,,,

다음 썸트렌드의 유료 플랜 관련 내용은 나중에 자세히 포스팅하도록 하겠습니다!
한 달 알차게 쓸 거예요....ㅠ...
어떤 데이터를 얻었는지, 어떻게 활용할지에 대해서는
잠시 후, 이번 포스팅의 데이터 전처리 부분에서 자세히 설명해드리도록 하겠습니다.
그럼 이제 대망의 사례 분석의 가장 중요한 부분인
데이터 전처리 및 모델링을 진행해볼까요?!
나 홀로 분석 프로젝트 (8) 사례 분석 및 비교
: 모델링(Two-sample t-test&One way ANOVA)
우선 데이터 전처리 이전에, 분석 대상을 정해볼까요?
저번 포스팅에서도 살짝 언급했듯이
TSK의 데이터가 그냥 언뜻 보기에도 괜찮은 데이터들이 많이 얻어진 편이라서
TSK를 먼저 분석을 진행해본 후에, 유의미한 결과가 나온다면 TSK만 진행하도록 하겠습니다.
만약 분석 과정에서 손쉽게 결과가 얻어질 경우에는, 다른 분석 대상들 또한 분석을 진행할까 합니다.
TSK의 TSK 서포터즈는 2020년 7월 20일부터, 8월 23일까지 약 한 달 정도 진행되었습니다.
이때를 기준으로 삼아서 어떻게 데이터를 활용할 것인지 생각해보겠습니다.
[데이터 전처리]
그럼 이제 데이터 전처리 과정을 위해서
간략하게 사용할 데이터에 대해서 정리 및 요약을 진행해보도록 하겠습니다.
<사용할 소비자 데이터>
1. 네이버 데이터랩 : 최근 1년 사이(2019.10.22~2020.10.22) 검색어 'TSK'에 대한 검색량

데이터를 잘 살펴보면 위의 그래프 상에 제가 별도로 표시한 부분이 의미가 있어 보이는데요..
- 노랑 형광펜 표시 부분 : 8월 27일, 검색량 급증하기 시작한 시점
- 빨강 펜 표시 부분 : 8월 31일, 기간 내 검색량이 가장 많은 시점
서포터즈 활동 종료 시점인 8월 23일을 기준으로
4일 후부터 급격히 검색량이 증가했고, 31일에 최대치를 찍었습니다.
아무래도 소비자들이 인지하기까지 시간이 걸린다는 것을 염두에 두었을 때에
한 달 정도의 활동이 끝나고 나서 반응이 나타나는 것은 꽤 유의미하다는 생각이 듭니다.
2. 다음 썸트렌드 : 최근 1년 사이(2019.10.30~2020.10.22) 관심도(언급량)

아무래도 1년 사이의 TSK에 대한 언급량을 조회하다 보니
올해 1월에 꽤 큰 언급량 수치 데이터 또한 수집되었습니다.
저 기간 동안 TSK 관련 어떤 이슈가 있었는지에 대해서는 알지 못하기도 하고,
딱히 제가 원하는 데이터가 아니기 때문에.. 저 기간의 데이터는 제거할까 합니다.
<데이터 처리 방향>
일단 before와 after로 나누기 위해서는 구분을 위한 특정 시점을 정해야 하는데,
그 시점을 어떻게 정해야 할지 조금 고민이 있었습니다.
TSK 서포터즈 활동 기간 외에도, 서포터즈 모집 기간에도
서포터즈 활동으로 인한 언급량 증가 또한 기대해볼 수 있기 때문에
모집 기간의 시작인 7월 1일을 기준으로 분석을 진행하고자 합니다.
물론 유의미한 분석 결과를 내기 위해서 결과가 맘에 들지 않는 경우(?)에는 기간을 바꿀 수 있습니다!
데이터는 네이버 데이터랩의 경우는 엑셀로 얻어졌기 때문에 그대로 txt로 변환하고 가공할 예정이며,
다음 썸트렌드는 일일이 타이핑해서.. txt 문서로 만들어야 할 것 같습니다 ^^..ㅠ....
[분석 모델링 : Two-sample t-test 분석 & One way ANOVA 분석]
모델링 과정에서 많은 어려움이 있었습니다,,,,눈물이 앞을 가ㄹ....
그래서 멘토님에게 구질구질하게(?) 메일을 보내서 문제를 해결하였죠,,,,
원래는 대응 표본 t-test 분석을 진행하려고 하였으나 이것은 데찔이인 저의 판단 오류였고,
멘토님의 도움 덕분에 모델링을 위해 어떤 분석을 진행해야 할지 알 수 있었습니다!
그래서 저는 이번 모델링 및 분석에서는
Two-sample t-test 분석과 One way ANOVA(일원 분산분석)을 진행하기로 결정했습니다.
[분석 목표]
서포터즈를 해당 기업의 이벤트라고 했을 때,
'TSK의 TSK 서포터즈'의 이벤트 진행 이후 TSK의 인지도에 유의미한 변화가 있었는지 확인.
1. 가설 설정
분석 목표를 달성할 수 있도록, 본격적인 모델링 과정에 앞서 가설을 설정해볼까요?
H0(영가설, 귀무가설) : 서포터즈 활동 전후에 대한 TSK의 인지도 차이는 없을 것이다.
H1(연구가설, 대립가설) : 서포터즈 활동 전후에 대한 TSK의 인지도 차이는 있을 것이다.
<귀무가설과 대립가설>
여기서 잠깐!
귀무가설, 대립가설은 무엇일까요?
사실 어느 정도 데이터 분석에 대해서 공부하시는 분들은
저 차이에 대해서 다들 아시겠지만, 간단하게 정리하고 가볼까요?
귀무가설이란?
귀무가설 또는 영가설이라고 하며, 간단하게 분석 과정에서는 H0으로 표현하곤 합니다.
어떠한 가설에 대한 차이가 없거나 의미 있는 차이가 없다는 가설을 말합니다.
한마디로 정리하자면 이 데이터 분석에서 유의미한 차이가 없다, 의미가 없다를 이야기하는 것입니다.
대립가설이란?
대립가설 또는 연구가설이라고 말합니다. 간단하게 H1으로 표현하기도 합니다.
귀무가설(영가설)에 대립하는 의미를 가지는 명제이자 용어로,
가설에 대해서 유의미한 차이, 의미가 있다를 이야기합니다.
보통 통계 및 분석 결과를 요약하고 정리하는 과정에서,
H0 : ~~~
H1 : ~~~
이렇게 가설을 설정 및 정리를 하기도 합니다.
그리고 결과에 대해서 이야기할 때는
영가설이 기각되었다. = 대립가설이 채택되었다.
귀무가설이 채택되었다. = 연구가설은 기각되었다.
이런 식으로 정리하고는 합니다.
저도 데이터 분석 수업 수강하면서도
한 가지 뜻에 대해서도 여러 가지 단어? 용어가 사용되기 때문에 좀 많이 헷갈렸던 것 같습니다..
계속 쓰다 보면 익숙해지기도 하고,
귀무가설은 없을 무(無)를 사용하기 때문에 H0의 0과 같고
차이가 없다의 없다를 사용한다 이런 식으로 연상을 해서 기억했습니다...
여하튼,,, 다시 돌아가 볼까요?
결국 이번 분석의 목표는
TSK 서포터즈 활동으로 인해 TSK의 인지도가 상승했다는 것을 증명하는 것이죠!
2. 데이터 전처리 : Data Load 함수 setting
참고할 튜토리얼 과정 중 첫 번째는 'Two-sample T-test'입니다.
링크 및 참고 파일은 다음과 같습니다.
①

Brightics Studio
www.brightics.ai
두 번째로 참고할 튜토리얼은 'ANOVA와 사후 검정'입니다.
링크 및 참고 파일은 다음과 같습니다.
②
Brightics Studio
www.brightics.ai
참고는 참고이므로,
저처럼 데이터 분석과 Brightics 사용에 대해서 조금 서투른 분들은
함께 열어 놓고 참고하시는 걸 추천드릴게요!
이제 본격적으로 모델링을 시작해볼까요?
Brightics Studio에 접속해서 새로운 모델을 생성해보겠습니다.
그다음은 Data Load를 위한 함수, 우리의 'Load'를 만들어볼까요?!
알아보기 쉽게 함수를 생성했으니 데이터를 업로드해줘야겠죠?
앞서 말했던 것처럼 데이터 처리 방향은 7월 1일을 구분 기점으로 삼을 것이기 때문에,
7월을 기준으로 5월과 6월을 이전(before)으로 삼고
8월과 9월을 이후(after)로 삼는 것으로 하고
이 기간 동안의 데이터를 사용하도록 하겠습니다.
그렇게 간단하게 정리를 마친, 네이버 데이터랩의 데이터는 다음과 같습니다.
그리고 노가다(?)의 작업을 통해 나온 다음 썸트렌드 데이터는 다음과 같습니다.
이 데이터를 Load 함수에 연결해주도록 하겠습니다.
참고로 Local PC에서 업로드 과정에서 데이터 가공 중 특별한 점은 얼마 없지만,
Delimeter는 Tab으로, Column name은 영어로 바꿔주시면 됩니다.
이제 데이터를 전처리하는 과정으로 넘어가겠습니다.
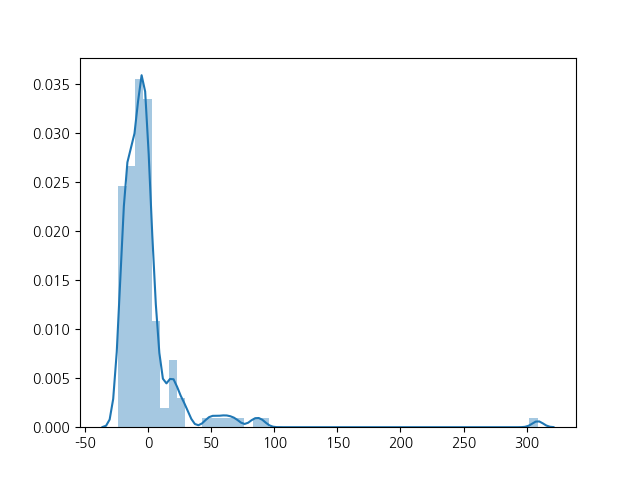
이 데이터는 단순히 날짜와 언급량 및 검색량인 인지도 수치 데이터이기 때문에,
저희가 보기에는 서포터즈 활동 전후를 알 수 있지만
컴퓨터나 처음 보는 사람들은 모를 수밖에 없거니와 분석을 더더욱 진행할 수 없는 상태입니다.
그렇기 때문에 추가적인 Column을 생성해서 서포터즈 활동 유무를 구별하도록 하겠습니다.
참고로 데이터가 두 개이기 때문에, 분석에 사용되는 함수와 과정 및 방법을 동일하게
datalab과 Sometrend로 두 번 진행하도록 하겠습니다!
'Add Column'이라는 함수를 사용하겠습니다.
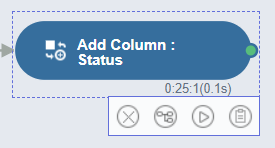
Status라는 Column은, 서포터즈 운영 유무를 구별하기 위한 Column으로
전후 비교를 위해서 꼭 필요한 함수입니다.
2020-07-01 이전은 문자 N으로 운영하지 않았음을 구별하고,
2020-07-01 이후는 문자 Y로 운영했음을 구별합니다.
구별을 위해 Add Column을 위한 조건문 설정은 다음과 같습니다.

New Column Type은 String, Expression Type은 Python으로 설정해주시고
Condition은 아래와 같이 "Date < '2020-07-01', N"으로, 나머지는 else 문에서 자동으로 'Y'로 표시되도록 해주시면 됩니다.
(저 간단한 Condition은 하다가 헤매서 1시간 걸렸는데,,,,,,천사 동규님께서 도와주셨습니다,,,,ㅠ0ㅠ)
저렇게 설정을 맞춘 뒤에 Run을 하면 결과는 다음과 같습니다.

성공적으로 7월 1일을 기점으로 활용 유무가 달라지는 것을 확인할 수 있습니다.
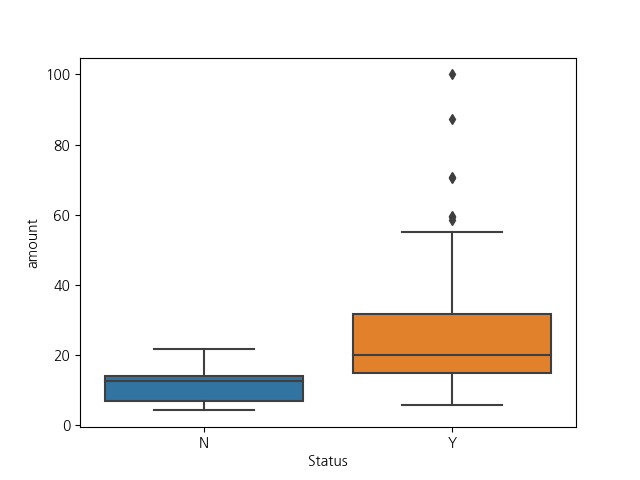
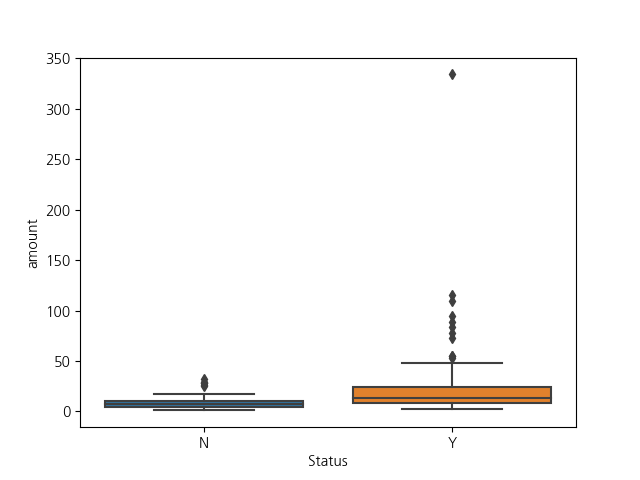
추가적으로 활동 유무에 따른 차이를 확인하기 위해 Line Chart와 Box Plot을 사용해보았습니다!
참고로 Line Chart의 옵션 중 특이사항은 다음과 같고,

Box Plot의 Chart 옵션은 다음과 같습니다.

어느 정도 데이터를 로드하고서 전처리 과정을 간단하게 마쳤으니,
Statistic Summary 함수를 이용해서 서포터즈 운영 여부에 따른 요약 통계량을 확인해보겠습니다.

Input Column으로는 Amount를 넣어주고,
Target Statistic은 Average, Number of value, Q1, Median, Q3를
Group By는 구별을 위해 Status를 입력해주시면 됩니다.
Run 해주시면 다음과 같은 결과가 나타납니다.

3. 분석 모델링 : Two Sample t-test & ANOVEA 관련 함수 setting
대충 요약 통계량을 확인했으니
본격적인 분석을 진행해보도록 하겠습니다.
우선 두 분석의 차이? 개념을 한번 짚어보고 분석을 진행해볼까요?
1) Two-sample T-test (이표본 t-검정)
우선 t-test는 '두 집단 간 평균 간의 차이를 검증하기 위한 분석 방법'을 말합니다.
t-test를 통해서 나오는 t-value는
'평균 간 차이가 어느 정도인지를 표본수(n) 및 표준오차(Standard Error)로 계산한 검정 통계량'입니다.
표준 오차는 표본 자료로 구한 평균이 모집단에서 어느 정도 틀릴 수 있는 가(오차 정도)를 계산한 값입니다.
또 하나의 중요한 개념은 유의 확률(p : probability)입니다.
검정 통계량인 t-value 값을 0과 1 사이의 확률로 표준화하여 계산한 값으로,
통상 유의 수준 0.05보다 작으면 유의미한 차이가 있다고 판단합니다.
간단하게 말해, t-검정은 두 평균의 차이를 검증하기 위한 분석 방법이며
종류에는 일표본 t-검정, 이표본 t-검정, 독립 표본 t-검정, 대응표본 t-검정이 있습니다.
일표본 t-검정은 한 집단의 표본 평균이 알려진 평균과 차이가 있는 가를 검증하는 분석 방법이고,
이표본 t-검정은 두 개의 독립적인 모집단에서 추출된 표본을 이용하여 두 집단의 모평균을 비교하는 검정입니다.
독립표본 t-검정은 두 표본 집단 간에 평균의 차이가 있는 가를 검증하는 분석 방법이며,
대응표본 t-검정은 동일한 집단에서 두 변수의 평균이 다른가를 검증하는 분석방법입니다.
분석 과정은 다음과 같습니다.
1. 두 집단 혹은 두 변수의 평균/표준편차/n 수를 계산
2. 계산된 통계량으로 새로운 t 분포를 기준으로 삼는다.
3. 평균 차이 정도를 계산한 검정 통계량인 t-value를 계산
4. 위 과정의 결과를 바탕으로 귀무가설과 대립가설 채택
2) One-way ANOVA (일원배치 분산 분석)
ANOVA는 ANalysis Of Variance, 분산 분석을 의미합니다.
ANOVA는 보통 세 집단 이상의 집단 평균치의 차이를 검정하는 데 적용되는 편입니다.
t-test와 다르게, ANOVA는 f-value을 사용합니다.
F-value는 F 통계량이라고도 불리며,
집단 간에 평균 차이가 독립변수(요인)에 의해 얼마나 달라지는 가를 계산한 결과입니다.
One-way는 독립 변수가 1개라는 의미이며,
독립변수는 인자/요인(Effect/Factor)을 의미합니다.
독립변수의 하위 범주의 구성수에 따라 level(수준)으로 나뉩니다.
독립변수가 3개 이상일 경우에는 t-test를 이용할 수 없는데,
독립 변수가 1개이더라도 level이 3 이상인 경우에도 t-test를 이용할 수 없습니다.
분산분석은 집단 간 분산, 집단 내 분산을 이용해서 분석합니다.
집단 간 분산(Variance Between Groups)은 전체 평균과 각 집단의 평균의 차이 정도를 의미하며,
집단 간 분산이 클수록 독립변수(요인)에 따른 효과(평균 차이)가 크다는 것을 의미합니다.
집단 내 분산(Variance Within Groups)은 집단의 평균과 각 자료의 값의 차이 정도를 의미하며,
집단 내 분산이 클수록 독립변수(요인)에 따른 효과에 오차 정도가 크다는 것을 의미합니다.
이 값들을 바탕으로 그룹 간 변동이 그룹 내 변동보다 크면 그룹 간에 차이가 있다고 검정하는 방법입니다.
3) Levene의 등분산 검정, F 검정
이 검정은 등분산 가정 결과를 파악할 때 사용되는데,
독립 집단, 각 집단의 분산이 동일한지를 검사해주는 것입니다.
F값의 유의 확률이 0.05보다 크면 '집단의 분산이 같다'라고 할 수 있습니다.
이때, 등분산이 가정되므로 '등분산이 가정됨'을 바탕으로 계속 분석을 통해 가설을 검정하면 됩니다.
이 검증은 다른 분석들의 유의 확률 판단 기준과 다르기 때문에 유의해야 합니다!!
특히 ANOVA는 그룹 간 분산의 동질성 가성에 민감한 편이기 때문에,
등분산 가정이 만족되는 경우에만 ANOVA를 수행하는 것이 좋습니다!
사실 제가 계속 Two-sample T-test와 ANOVA, 두 개를 언급했는데
두 개 분석 모두가 필요한 것이 아니라 둘 중에 하나라도 사용하면 결과는 알 수 있습니다.
그러니 입맛(?)에 맞는 대로 고르시면 됩니다!
저는 멘토님이 알려주신 보람이 있으시도록 둘 다 진행해보도록 하겠습니다!
1) Two-Sample T-test (이표본 t-검정)
우선 Two-Sample T-test 함수를 이용하기 전에,
위에서 언급했던 등분산 검증을 하도록 하겠습니다.
이 결과에 따라 분석의 방법이 달라지기 때문에, 꼭 거쳐야 하는 과정입니다.
등분산 가정을 만족시키는지를 확인하기 위해 'F Test For Stacked Data'라는 함수를 이용하겠습니다.
Factor Column별 등분산성 검정을 수행합니다.
함수 옵션은 다음과 같이 설정하면 됩니다.


Response Column은 Amount, Factor Column은 Status로 설정하고
First는 서포터즈 활동 유무 Yes인 Y, Second는 No인 N입니다.
datalab의 데이터를 바탕으로 한 결과는 다음과 같으며,

Sometrend 데이터를 바탕으로 한 결과는 다음과 같습니다.

등분산 검정의 귀무가설은 "두 분산의 비율이 1이다. 즉, 두 분산이 동일하다"입니다.
p-value가 0.05보다 크기 때문에 귀무가설을 기각할 수 없습니다.
즉, 두 그룹의 분산은 동일하다고 볼 수 있습니다.
이 결과를 토대로 Two-Sample T Test For Stacked Data 함수의
'Assume Equal Variances' 옵션 값을 'True'로 지정할 예정입니다.
이번에는 정말로 Two-sample T-test 함수를 사용하겠습니다!
정확히는 Brightics의 'Two Sample T Test For Stacked Data'를 사용하겠습니다.
Factor Column별 Response Columns의 평균값이 유의한 차이를 보이는지를 검정하게 됩니다.
이렇게 함수를 연결 및 생성을 해주시면 됩니다.

함수 옵션 값은 다음과 같이 설정하면 됩니다.
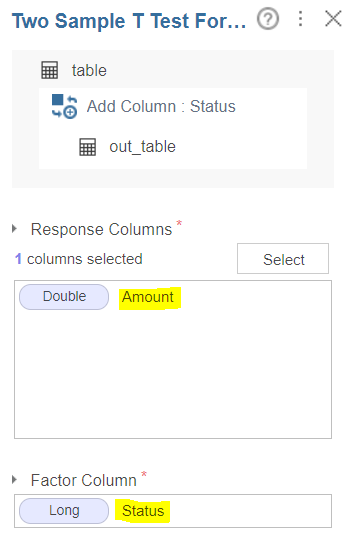
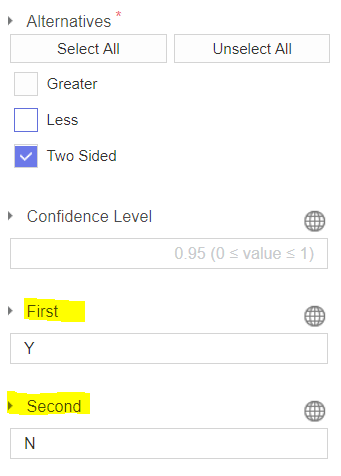

Response Column은 Amount, Factor Column은 Status입니다.
그 이후부터는 방금 전의 등분산 검정 과정과 옵션 설정이 동일하지만,
'Assume Equal Variances' 부분은 다릅니다.
원래는 Auto로 설정해도 자동으로 등분산 검정을 수행하고
그 결괏값을 토대로 t-검정을 수행해서 그에 맞는 분석을 진행하지만,
이미 등분산 검정을 수행해서 확인했기 때문에 이 부분을 'True'로 설정해주시면 됩니다.
결과는 방금의 순서와 같이 datalab, Sometrend의 순서로
다음과 같습니다.

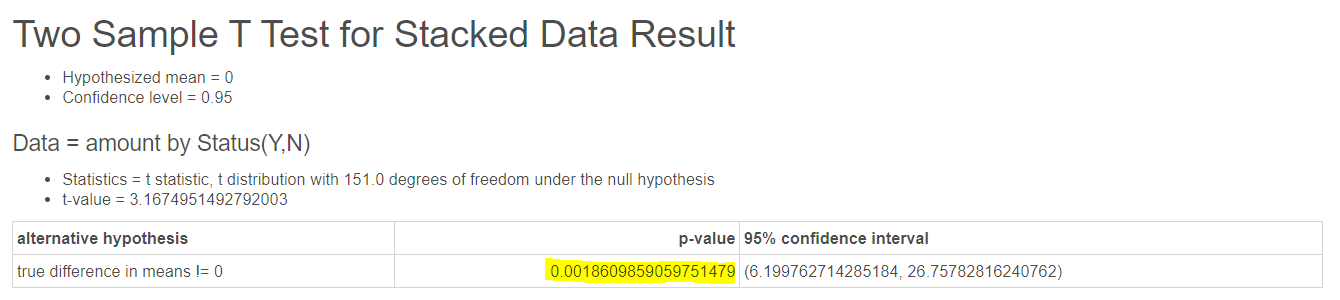
이 결과를 보시면 아시다시피, datalab과 Sometrend의 결과가 다릅니다..!
datalab 데이터 바탕으로 분석을 진행한 결과, 유의 확률이 0.05보다 크게 나왔고
Sometrend 데이터 바탕의 분석 결과는 유의 확률이 0.05보다 작게 나왔음을 알 수 있습니다.
이번에는 ANOVA를 해보도록 하겠습니다.
함수는 'One Way ANOVA'를 사용하며, 다음처럼 생성해주시면 됩니다.
함수 옵션은 다음과 같이 설명하시면 됩니다.

T-test와 다르게 Response와 Factor Column만 설명해주면 됩니다!
사실 결과는 보지 않아도 알 수 있.....! 는 이유는
ANOVA는 T-test의 확장판으로, 역시 결괏값은 앞에서 수행한 T-test와 동일하기 때문이죠!
F 통계량은 t 통계량의 제곱이며, 그에 따른 p-value는 동일합니다.
분석 결과는 다음과 같습니다.
One-way Analysis of Variance Result
amount by Status
ANOVA
dfsum_sqmean_sqFPR(>F)| Status | 1.0 | 8483.93978863731 | 8483.93978863731 | 41.80030451633257 | 1.3216221452122343e-09 |
| Residual | 151.0 | 30647.501804291434 | 202.9635881078903 | nan | nan |
Diagnostics
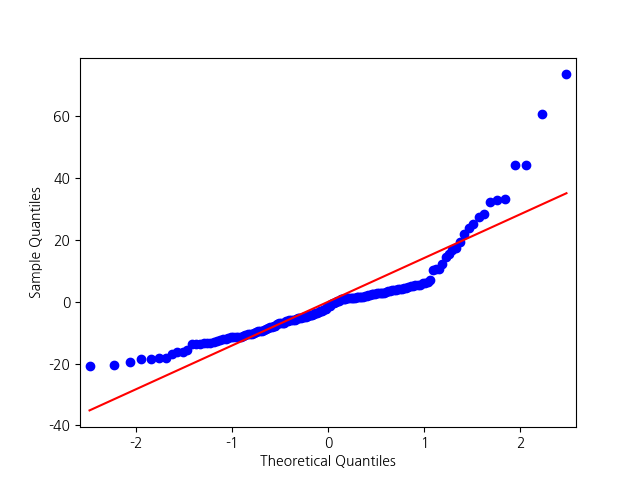
One-way Analysis of Variance Result
amount by Status
ANOVA
dfsum_sqmean_sqFPR(>F)| Status | 1.0 | 9960.408649299567 | 9960.408649299567 | 10.033025520707243 | 0.0018609859059751696 |
| Residual | 151.0 | 149907.09461867428 | 992.7622160177104 | nan | nan |
Diagnostics
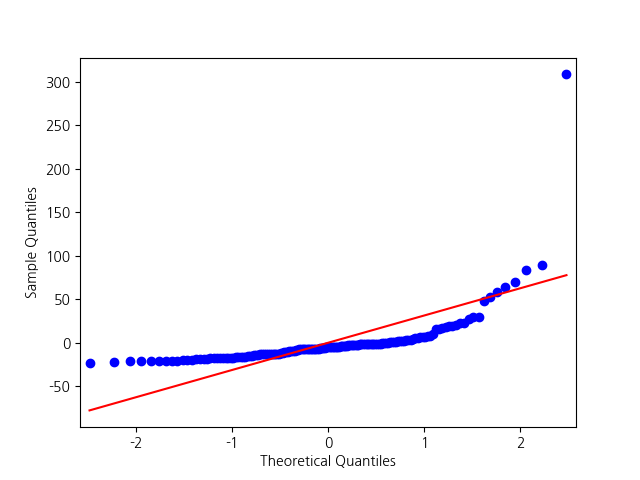
결과는 T-test의 결과와 동일함을 알 수 있습니다.
끄읏-!!!!!!!!!!!!!!!
그렇습니다......
네이버 데이터랩을 통해서 얻은 데이터로는 유의미한 결과를 얻을 수 없었고,
다음 썸트렌드를 통해서 얻은 데이터로는 유의미한 결과를 얻을 수 있었습니다..!
어쩌다 보니.. 다음 썸트렌드 데이터를 유료 결제한 것이 신의 한 수가 되어버ㄹ.......
오늘 포스팅은 유독 길었네요...!
결과 및 인사이트에 대한 포스팅을 하는 것은 다음 포스팅에서 진행하도록 하겠습니다.
분석만 하고 얼렁뚱땅 넘어가는 것은 정말 아닙니다!!!
그럼 다음 포스팅에서 만나요, 안녕!
٩(ˊᗜˋ*)و
** Brightics 서포터즈 활동의 일환으로 작성한 포스팅입니다 **
'Data Analysis '◡'✿ > 삼성SDS Brightics AI & Studio' 카테고리의 다른 글
| [Brightics 서포터즈] 나홀로 분석 프로젝트(10) 가상 제안서 작성 : 데이터 분석 기반 제안서 (0) | 2020.11.17 |
|---|---|
| [Brightics 서포터즈] 나홀로 분석 프로젝트 (9) 데이터 분석 결과 보고서 : 인사이트 도출 및 최종 결과 정리 (3) | 2020.11.09 |
| [Brightics 서포터즈] 나홀로 분석 프로젝트 (7) 사례 분석 및 비교 : 데이터 수집 (0) | 2020.10.23 |
| [Brightics 서포터즈] 나홀로 분석 프로젝트 (6) 시장 내 포지션 분석 (+시각화) (0) | 2020.10.13 |
| [Brightics 서포터즈] 나홀로 분석 프로젝트 (5) 시장 내 포지션 분석 (0) | 2020.10.04 |



