
안녕하세요, Soa입니다!
٩(ˊᗜˋ*)و
오늘은 팀 프로젝트를 본격적으로 실습해보도록 하겠습니다!
이번 프로젝트는 동규님이 저희의 멘토나 다름없습니다!
이미 이 프로젝트를 해본 경험이 있으시고, 소스를 제공해주셨기 때문이죠~
(동규님 짱!)
취뽀 하셔서 이제 연수 들어가셔야 하는데, 들어가기 전에 끝까지 모델링 팁도 주시고 가셨답니다!
자, 그럼 한번 실습을 시작해볼까요?
"Brightics로 학교 과제 날로 먹었다!"
(부제 : 온라인 쇼핑몰 이용객 데이터 분석 과정과 인사이트 도출 실습)
두 번째 이야기, 모델링 실습
저번 포스팅에서도 설명했듯이
Kaggle 사이트의 data를 사용해서 분석을 진행할 예정입니다.
터키의 온라인 쇼핑몰 이용객 데이터인데, 자세한 설명은 바로 다음 데이터 수집 단계에서 이야기드리겠습니다.
[데이터 수집]
저번 포스팅 링크에서도 첨부한 링크이지만, 이번 포스팅을 주로 보고 참고하실 테니 한번 더 첨부하겠습니다!
이번 분석에서 사용하게 될 터키의 온라인 쇼핑몰 이용객 데이터입니다.
Online Shoppers Intention UCI Machine Learning
Online Shopper Intention Dataset from UCI's Machine Learning Library
www.kaggle.com
이 링크들 들어가면 이렇게 사이트가 나타납니다.

여기에서 "Download(252KB)"를 클릭해주시면 다운로드가 가능합니다.
이 사이트에 아이디가 없으신 분들은 다음과 같은 창이 뜰 겁니다!

저는 구글로 로그인했고, 중간에 뭐 광고 동의는 체크는 안 했습니다!
그렇게 얻은 데이터는 요것!
데이터와 그 특성에 대해서 간략하게 설명해보자면, 원본 데이터 설명 페이지를 참고했습니다.
원문은 영어였는데, 번역기 사용해서 번역한 터라.. 조금 어색할 수 있습니다.
데이터 집합은 10개의 숫자 속성과 8개의 범주형 속성으로 구성된다.
'Revenue' 속성은 클래스 라벨로 사용할 수 있다.
"Administrative", "Administrative Duration", "Informational", "Informational Duration", "Product Related" 및 "Product Related Duration"은 해당 세션에서 방문자가 방문한 다양한 유형의 페이지 수와 이 페이지 범주에서 사용된 총시간을 나타낸다.
이러한 기능의 값은 사용자가 방문한 페이지의 URL 정보에서 파생되어 사용자가 조치를 취할 때(예: 한 페이지에서 다른 페이지로 이동) 실시간으로 업데이트된다.
"Bounce Rate", "Exit Rate" 및 "Page Value" 기능은 전자상거래 사이트의 각 페이지에 대해 "Google Analytics"이 측정한 측정 지표를 나타낸다.
웹 페이지에 대한 "Bounce Rate" 기능의 값은 세션 중에 분석 서버에 다른 요청을 트리거하지 않고 해당 페이지에서 사이트에 들어간 다음 ("bounce")를 떠나는 방문자의 비율을 의미한다.
특정 웹 페이지에 대한 "Exit Rate" 기능의 값은 세션에서 마지막이었던 비율인 페이지의 모든 페이지 뷰에 대해 계산된다.
Page Value 기능은 전자상거래 거래를 완료하기 전에 사용자가 방문한 웹 페이지의 평균값을 나타낸다.
"Special Day" 특성은 세션이 거래로 마무리될 가능성이 높은 특정 특별한 날(예:Mother’s Day, Valentine's Day)에 대한 현장 방문 시간의 폐쇄성을 나타낸다.
이 속성의 가치는 발주 일과 납품일 사이의 기간 등 전자상거래의 역학을 고려하여 결정된다.
예를 들어 Valentina’s day의 경우 이 값은 2월 2일부터 2월 12일 사이에 0이 아닌 값을 취하며, 다른 특별한 날에 가깝지 않은 한 이 날짜 전후에 0이 되고, 2월 8일에 최댓값이 1이 된다.
또한 데이터 집합에는 운영 체제, 브라우저, 지역, 교통 유형, 복귀 또는 신규 방문자로의 방문자 유형, 방문 날짜가 주말인지 여부를 나타내는 Boolean value, 연중 월이 포함된다.
음.. 주요 특징으로는 발렌타인 데이나 어버이날 같은 특정 이벤트가 있는 특수한 경우에는
그 날에 대한 현장 방문 시간의 폐쇄성을 수치화했습니다.
또, "Bounce Rate", "Exit Rate" 및 "Page Value" 기능은
전자상거래 사이트의 각 페이지에 대해 "Google Analytics"이 측정한 측정 지표입니다.
데이터 분석 과정에서 헷갈리는 개념이 있으면 이 부분을 참고하면 될 것 같습니다!
[데이터 전처리]
데이터를 무사히 얻었으니, 당연히!
Load 함수에 업로드해주면 되겠죠?!

요로코롬 그냥 하시던 대로 로드를 해주시면 되는데,
parameter는 Comma로 설정해주시면 됩니다!
그리고 데이터 전처리를 위해서 'Delete Missing Data' 함수를 사용하겠습니다.

까-알끔하게 전처리해주고 나면 본격적으로 데이터 시각화를 진행하면 됩니다.
[시각화 함수 모델링]
과제는 크게 "시각화"와 "상관관계 확인 및 회귀분석"으로 나눌 수 있습니다.
그래서 먼저 데이터 시각화를 위한 모델링 과정을 실습하면서,
데이터 시각화 실습을 진행하도록 하겠습니다.
데이터 시각화의 종류는 총 8가지로, 시각화를 진행한 내용은 다음과 같습니다.
1) 구매 여부에 따른 방문객 비율
2) 주말 고객 대상 구매 여부에 따른 방문객 비율
3) 방문 횟수에 따른 고객 유형 비율
4) 브라우저 이용 유형에 따른 방문객 비율
5) 페이지 성격에 따른 방문수
6) 지역에 따른 방문객 비율
7) 월별 방문 고객 수
8) 월별 구매 건수
시각화에 대한 함수 및 모델링은 전체적으로 이렇게 이루어지게 됩니다.

자세한 모델링 작업과 함수 설정에 대해서는 천천히 설명드리겠습니다!
1) 구매 여부에 따른 방문객 비율
가장 먼저, 구매 여부에 따라 방문객을 분류한 시각화 작업입니다.
정말 간단하게 온라인 쇼핑몰 페이지에 방문한 모든 고객들을 대상으로,
쇼핑몰 내 상품 구매 여부에 따라 구매한 고객과 구매하지 않은 고객으로 나누어 구분하는 시각화 작업입니다.
총 방문객 수는 row의 수와 같기 때문에

총 12,330명입니다.
이들을 구매 여부에 따라 나누어야 하는데, 나누는 기준이 되는 Column은 Revenue입니다.
Revenue는 매출, 수익이라는 뜻을 가지고 있죠?
이 칼럼은 방문이 거래로 마무리되었는지를 나타내는 Column입니다.
거래로 마무리된 경우는 True, 거래가 이루어지지 않은 경우는 False로 표시합니다.
이 경우에는 Statistic Summary 함수를 이용하도록 하겠습니다.

함수 설정 중 특이 사항은 다음과 같습니다.
Input Columns : Administrative
Target statistic : Number of row
Group By : Revenue
설정 후에는 Pie로 차트 형성을
이렇게 설정해주게 되면

이렇게 구매 여부에 다른 방문객 비율에 대한 차트를 얻을 수 있습니다!
2) 주말 고객 대상 구매 여부에 따른 방문객 비율
첫 번째 시각화 작업과 유사하지만, 모든 방문객 대상이 아니라
주말 방문 고객 대상에 한해 구매 여부에 따라 방문객들을 구분한 시각화입니다.
주말에 방문한 고객인지를 구별하기 위해 'Weekend'라는 Column을 이용했습니다.
이 칼럼은 True는 주말에 방문하여 구매했다는 의미이며, False는 구매하지 않았다는 뜻입니다.

Statistic Summary 함수와 Weekend Column을 이용해서 시각화해보겠습니다.
함수 설정의 특이 사항은 다음과 같습니다.
Input Columns : Administrative
Target statistic : Number of row
Group By : Weekend
그다음, 차트 설정은 Pie로 다음과 같이 해주시면 됩니다.

그럼 다음과 같은 차트를 얻을 수 있습니다.

3) 방문 횟수에 따른 고객 유형 비율
세 번째 시각화 작업에서는 방문 횟수에 따라 고객 유형을 나누었습니다.
관련된 Column 이름은 'Visitor Type'입니다.
처음 방문한 고객은 'New Visitor', 재방문 고객은 'Returning Visitor'로
그 외 고객들은 기타(Other)로 구분했습니다.
이번에도 동일하게 Statistic Summary 함수를 사용하겠습니다.
설정 사항은 다음과 같습니다.
Input Columns : Administrative
Target statistic : Number of row
Group By : Visitor Type
이번에도 비율을 나타내기 위해 Pie 차트를 사용하겠습니다.
차트 설정은 다음과 같이 해주세요!

그럼 다음과 같은 차트를 얻을 수 있습니다.

4) 브라우저 이용 유형에 따른 방문객 비율
이번 시각화는 방문객들을 브라우저(Browser) 이용 유형에 따라 구분한 시각화입니다.
사실 이 시각화는 진행하지 말지에 대해서 고민을 했었습니다.
왜냐하면 브라우저 유형에 대해서 1번부터 13번까지 나누어서 구분했지만
각 번호가 어떤 브라우저인지는 알 수가 없었습니다..
대충 크롬과 같은 유형들이겠지만 정확하게 모르니 인사이트를 찾을 수가 없기 때문이죠..
그래서 우선 시각화 후에! 나중에 자료를 찾게 되면 인사이트를 찾는 걸로 하기로 했습니다!
그래서 함수 설정은 다음과 같으며
Input Columns : Administrative
Target statistic : Number of row
Group By : Browser
차트 설정은 다음과 같습니다.

그럼 이렇게 시각화를 할 수 있죠!

5) 페이지 성격에 따른 방문수
페이지의 성격에 따라 방문수가 어떻게 달라지는지를 살펴보기 위한 시각화 작업입니다.
페이지의 성격은 총 세 가지로 나누어서 구분되어 있습니다.
1) Administrative Visit : 계정 관리 관련 페이지에 대한 방문
2) Informational Visit : 쇼핑 사이트의 웹 사이트, 커뮤니케이션, 주소 정보에 대한 방문
3) ProductRelated Visit : 제품 관련 페이지에 대한 방문
각 페이지 별로 방문 횟수에 따라 고객의 수를 시각화할 예정입니다.
세 가지의 페이지마다, n번 방문한 방문객이 몇 명인지 시각화한 자료라고 보시면 됩니다.
함수 구성, 모델링은 다음과 같이 했습니다.

Administrative, Informational, ProductRelated
이 세 가지 Column들을 각각 따로 빼내어서
Statistic Summary 함수에서 나온 표를 모두 합해서 시각화한 과정입니다.
우선 Select Column에서는 이렇게 조건을 설정해서 따로 빼내 주면 되며

Statistic Summary 함수에서는 Input Column과 Group By 모두,
Administrative로 설정하면 됩니다.
Informational나 ProductRelated 또한 마찬가지로 통일해주시면 됩니다.
target statistic은 이전에도 계속 써왔던 Number of row를 사용하면 됩니다.
그 후에는 Administrative과 Informational을 'Bind Row Column'으로 합치면 됩니다.
이 합친 걸 다시 ProductRelated와 합치면 세 가지 모두 합칠 수 있게 됩니다.
함수 설정은 매우 간단합니다.

이렇게 첫 번째 Row 혹은 Column을 선택하고, 두 번째를 선택하고
Row인지 Column인지를 선택하면 됩니다.
차트는 Column을 통해 다음과 같은 설정으로 시각화해주시면 됩니다.

그럼 이렇게 세 가지의 표가 탄생하게 됩니다!


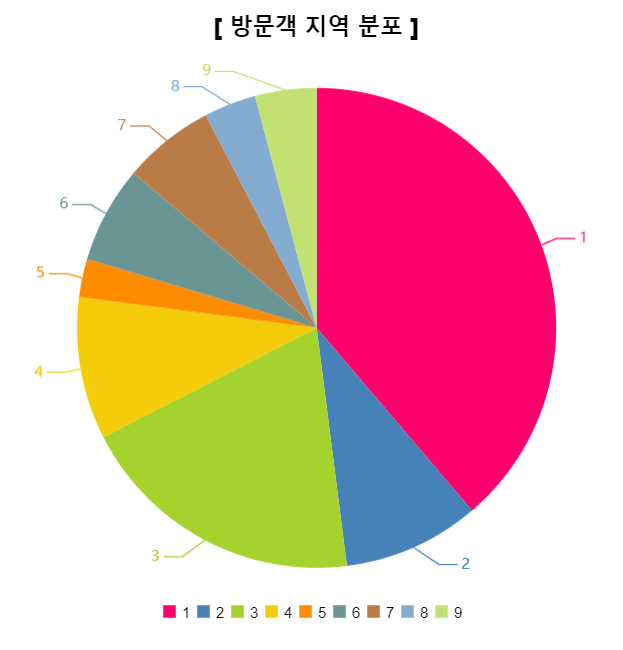
6) 지역에 따른 방문객 비율
방문한 고객들의 지역이 각각 어디이며, 그 비율이 어떤지에 대해서 나타내는 시각화 작업입니다.
브라우저 이용객 비율과 동일하게 이번 시각화 작업도 번호에 따른 지역이 무엇인지 모릅니다...ㅠ0ㅠ
그래서 이번에도 시각화 먼저 진행해본 뒤에, 나중에 정보를 얻게 되면 인사이트를 도출해내도록 하겠습니다.
이번에도 Statistic Summary 함수를 이용해서

Input Columns : Administrative
Target Statistic : Number of row
Group By : Region
이렇게 설정한 뒤에, 차트는 Pie로

이렇게 설정해주면 다음과 같은 차트를 얻을 수 있습니다!
7) 월별 방문 고객 수
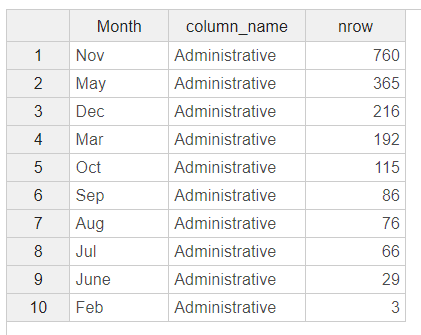
1년이라는 기간 동안, 매월마다 방문객의 수가 어떻게 되는지 표현하는 시각화 작업입니다.

우선 Statistic Summary에서
Input을 Administrative, target은 Number of row, Group By는 Month로 설정하면

이렇게 데이터 테이블을 얻을 수 있습니다.
사실 여기에서 끝내고 시각화를 할 수도 있습니다.
이번에도 역시나 Pie 차트를 사용하고, 설정은 다음과 같습니다.

그럼 다음과 같이 시각화를 할 수 있습니다.

그리고 Sort 함수를 통해서는 월별 방문 고객 수의 크기에 따라 정렬할 수 있습니다.

이 세팅 조건을 통해서 Sort 함수를 이용하게 되면
다음과 같은 정렬된 테이블을 얻을 수 있습니다.

8) 월별 구매 건수
마지막으로, 월별로 방문 고객들의 구매 건수 추이가 어떻게 되는지에 대해서 시각화해서 살펴보도록 하겠습니다.
모델링은 먼저 방문객들 중 구매한 고객들만 Filter 함수를 통해 걸러준 후에,
Statistic Summary 함수로 월별로 구분 지어 시각화할 예정입니다.
Sort 함수로는 정렬을 진행할 예정입니다.

Filter 함수는 Revenue 칼럼을 이용해서 다음과 같이 설정해주면 됩니다.

Statistic Summary 함수는 다음과 같이 설정해주시면 됩니다.
Input Columns : Administrative
Target statistic : Number of row
Group By : Month
이렇게 설정해주신 후에는 차트 설정은 Pie로 해주시면 됩니다.

다음과 같이 시각화가 완성되었습니다!

마지막으로 Sort 함수는 조건은 이렇게 설정하시면

이렇게 정리된 테이블을 얻을 수 있습니다.
[통계 분석 함수 모델링]

통계 분석 종류는 총 3가지로, 내용은 다음과 같습니다.
1) 월별 이탈률, 종료율 분포
2) 이탈률과 종료율 간 유의미한 상관 관계 여부 판별 위한 상관 관계 분석 (+ 고객 유형에 따라)
3) 이탈율과 종료율 간의 선형 관계 측정 위한 선형 회귀 분석 (+ 고객 유형에 따라)
이탈률(Bounce rate)은 웹사이트를 방문한 사용자가 처음 접속한 페이지에서 아무런 행동도 하지 않고
종료할 경우를 이탈이라고 정의하고, 이탈 횟수를 방문객 수로 나눈 값을 백분율로 표현한 것이 바로 이탈률입니다.
여기서 Bounce rate는 페이지별 이탈률들의 평균값을 말합니다.
종료율(Exit rate)은 웹사이트를 방문한 사용자가 이탈되지 않고,
1개 이상의 페이지를 탐색한 후에 마지막으로 탐색한 페이지 뷰 수에 대한 비율로 정의되며
마지막으로 탐색된 페이지 뷰 수를 해당 페이지의 총 페이지 뷰 수로 나눈 뒤 백분율로 표현한 것이 바로 종료율입니다.
Exit rate는 페이지별 종료율들의 평균값을 말합니다.
월별로 이탈률과 종료율의 분포가 어떻게 되는지 구해본 뒤,
이탈율과 종료율 간에 유의미한 관계가 있는지 알아보기 위해 상관관계 분석을 진행하고
고객 유형에 따른 차이가 있는지도 함께 살펴보겠습니다.
마지막으로는 이탈률과 종료율 간의 선형 관계 측정을 위해 선형 회귀 분석을 진행합니다.
이 분석 또한 고객 유형에 따라 차이가 있는지 추가 분석을 진행하고자 합니다.
1) 월별 이탈률, 종료율 분포
1월부터 12월까지, 월별로 방문객들의 이탈률과 종료율에 대한 비율 및 변화를 알아보기 위한 시각화 작업입니다.
Select Column 함수를 통해
세 가지(Bounce Rate, Exit Rate, Month)의 Column을 선택합니다.

선택한 칼럼은 오른쪽에 입력한 대로 이름 변경 또한 가능합니다.
함수의 결과를 토대로 다음과 같이 Box Plot으로 시각화하도록 하겠습니다.
설정은 다음과 같이 해주시면 됩니다.

그럼 다음과 같은 Box plot이 완성됩니다.


2) 이탈률과 종료율 간 유의미한 상관관계 여부 판별 위한 분석
이렇게 구한 이탈률과 종료율을 이용해서 상관 관계 분석을 진행하겠습니다.
유의미한 상관관계인지를 파악하기 위한 분석입니다.
상관관계란 말 그대로 변수 간의 유의미한 상관이 있느냐에 대한 관계를 의미합니다.
이 관계를 알아내기 위해서 상관관계 분석을 진행하며,
유의 확률과 상관 관계 계수를 통해서 결과를 해석할 수 있습니다.

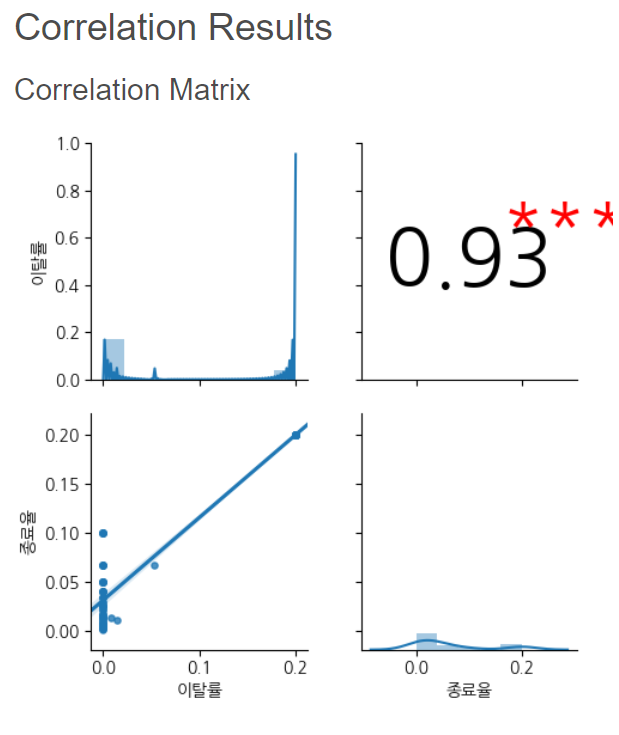
Correlation 함수를 사용하고, 세팅은 다음과 같이 해주시면 됩니다.

Pearson의 상관관계 분석을 사용할 예정입니다.
그렇게 나온 분석 결과는 다음과 같습니다.


p-value가 0.0으로 종료율과 이탈률 사이에는 아주 강한 정(+)의 상관관계가 있는 것으로 나타났습니다.
또한 상관 계수가 약 0.913로 1에 상당히 가까운 숫자이므로 매우 강한 양의 상관관계임을 알 수 있습니다.
+ 고객 유형에 따른 상관관계 분석
고객 유형에 따른 상관 관계 분석을 위해
Select Column에서 Visitor Type 칼럼을 추가하고, 이름을 방문객 유형으로 변경하였습니다.
Correlation 함수를 복사하고, Group By에서 방문객 유형으로 추가해주면 됩니다!
[재방문 고객 대상 상관관계 분석]


[신규 방문 고객 대상 상관 관계 분석]


[기타 유형 고객 대상 상관 관계 분석]

고객 유형에 따라 상관 관계 분석을 진행한 결과,
재방문 고객 대상으로 진행했을 때 신규 고객 대상보다 더 강한 상관관계가 관찰되었으며
기타 고객 대상에서는 상관관계가 유의미한 상관 관계가 나타나지 않았습니다.
3) 이탈률과 종료율 간의 선형 관계 측정 위한 선형 회귀 분석
이탈률과 종료율 간에 선형 관계 측정을 위해서 선형 회귀 분석을 진행하겠습니다!
선형 관계란 영향을 주는 독립 변수와 영향을 받는 종속 변수 간 관계가 수학식으로 표현되는 것을 말합니다.
"Y= a+bX"처럼 선형 관계인지를 파악하는 것인데,
Y는 종속 변수, X는 독립 변수입니다.
b는 회귀 계수로 그 크기와 방향성으로 독립 변수가 종속 변수에 미치는 영향을 알 수 있게 됩니다.
a는 X의 값이 변해도 Y의 변동에는 영향을 주지 않는 회귀 계수입니다.
이외에도 다른 영향을 주는 영향력들은 오차항에 포함되기도 합니다.
회귀 분석을 통해서 변수 간의 회귀식을 도출하고, 이를 통해 결과를 분석하게 됩니다.
이 과정 속에서 여러 가정들을 충족시키는지 확인합니다.
어떤 가정들이고 어떻게 해석하는지는 결과 해석하면서 설명하겠습니다.
그래서 회귀 분석 모델링은 다음과 같이 진행하겠습니다!
첫 번째는 이탈률과 종료율 간의 회귀 분석을 진행하고,
두 번째는 고객 유형에 따른 이탈률과 종료율 간의 회귀 분석을 진행할 예정입니다.

함수 설정은 이렇게 해주시면 됩니다.

실행해주면 다음과 같은 결과창이 나타납니다.





결과 요약에 따르면,유의 수준(P-value)이 0으로 매우 유의하고
R-Square는 약 83%의 설명력을 나타내고 있습니다.
잔차의 산점도를 이용한 등분산 성과 Q-Q plot을 통해 잔차들의 정규성을 확인해보면,
잔차의 산점도가 아주 무작위로 분포해있지는 않은 것 같은데..
Q-Q plot은 그래도 직선에 가깝게 정규분포에 가까운 것 같습니다...
이 부분은 유의미한 결과인지에 대해서 좀 이야기를 나눠보도록 하겠습니다..!
고객 유형에 따른 회귀 분석도 한번 진행해보겠습니다.
Group by ['방문객 유형'] : ['Returning_Visitor']
Linear Regression Result

Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Predicted vs Actual

Fit Diagnostics



Group by ['방문객유형'] : ['New_Visitor']
Linear Regression Result

Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Predicted vs Actual

Fit Diagnostics



Group by ['방문객유형'] : ['Other']
Linear Regression Result

Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Predicted vs Actual

Fit Diagnostics



고객 유형에 따른 회귀 분석을 진행해본 결과, 재방문 고객의 경우는 전체 분석과 매우 유사했습니다.
신규 고객과 기타 고객의 경우, 잔차의 산점도를 이용한 등분산 성과 Q-Q plot을 통해 잔차들의 정규성을 확인해보면
이게 무작위로 분포되어 있다고 하기도 좀 그렇고..
제 판단에는 충족시키지 못하는 것 같다는 생각이 들었습니다..
이 부분 또한 같이 생각을 해봐야 할 것 같습니다..!
끄읏...!
이번 포스팅에서는 분석 모델링 실습을 통해서 과제 부분은 마무리하도록 하겠습니다.
다음 포스팅에서는 분석 결과를 토대로
인사이트를 도출하고 팀원들과 함께 인사이트를 공유하는 과정을 담도록 하겠습니다!
생각보다 긴 포스팅이었네요...!
어느덧 막바지를 달려가고 있는 Brightics 서포터즈!
끝까지 열심히! 화이팅!
그럼 다음 포스팅에서 만나요~
모두 안뇽!
٩(ˊᗜˋ*)و
** Brightics 서포터즈 활동의 일환으로 작성한 포스팅입니다 **



