
안녕하세요, Soa입니다!
😊
저번 포스팅에서는 기본 시나리오를 바탕으로 Brightics를 실습해보았습니다!
[Brightics AI] Brightics Studio 사용법 : 기초편 (3) 기본 시나리오 실습
안녕하세요, Soa입니다! 😊 저번 포스팅에서는 차트 기능과 셋팅 방법에 대해서 알아보고 간단하게 실습을 진행했습니다! [Brightics AI] Brightics Studio 사용법 : 기초편 (2) Chart 실습 안녕하세요, Soa입
soa-park.tistory.com
이번 포스팅에서는 종합 시나리오를 바탕으로 실습을 진행해보겠습니다.
■ 종합 시나리오 (Composite Scenario)
먼저 종합 시나리오 과정은 회귀분석과 군집분석으로 이루어져 있습니다.
간단하게 회귀분석과 군집분석에 대해서 알아보겠습니다.
1. 회귀분석 (Regression Analysis)
독립변수와 종속 변수 간의 관계를 파악하는 데 사용되며,
두 변수 간의 관계의 구체적 방향과 크기를 회귀식(regression line)을 통해 제시합니다.
회귀분석의 목적은 영향의 정도, 통제 효과 등의 구체적 관계를 통해
종속변수의 변화를 예측하는 것입니다.
종속변수에 미치는 영향요인(독립변수)의 개수에 따라
단순 회귀분석과 다중회귀분석으로 구분할 수 있습니다.
(다중회귀분석이 실제 분석에서 더 많이 사용)
회귀분석은 약 6가지 정도의 가정을 충족시켜야 합니다.
변수 간의 선형 관계, 오차의 정규성, 오차의 등분산, 오차의 독립성(잔차의 산점도), 다중공선성, 사례수
(SPSS에서는 표준화 잔차 정규 확률 도표와 잔차 산점도로 확인)
참고로 종합 시나리오에서는 선형 관계를 만족시키는 선형 회귀분석을 사용할 예정입니다.
선형 관계식을 평가하는 방식을 Hold-Out Test라고 합니다.
과정은 다음과 같습니다.
1) 데이터를 Train Data와 Test Data로 분리해 Train Data로 훈련시켜 모델을 구축합니다.
2) 모델 성능 평가를 위해 Test Data를 사용해 예측치를 구해 출력 결과와 비교합니다.
이런 과정을 거쳐 선형 관계식을 평가하게 됩니다.
2. 군집분석 (Clustering Analysis)
군집분석은 군집 내 유사성과 타 군집 내 상이성을 규명하는 통계 분석 방법입니다.
군집 분류 가정은 다음과 같습니다.
1) 군집 내 속한 객체들의 특성은 동질적이어야 한다.
2) 서로 다른 군집 내 객체들 간의 특성은 서로 이질적인 되도록 분류해야 한다.
개별 군집의 특성인 프로필은 각 군집 평균값으로 표현 가능한데,
군집분석은 군집 형태가 다양하기 때문에 까다롭습니다.
따라서 군집분석은 유사성이 중요한데,
유사성은 측정 방법에 따라 거리와 유사성으로 척도 기준이 나뉩니다.
또한, 군집 대상의 중복 여부와 자료의 크기에 따라서
계층적/비계층적 군집분석과 중복 군집분석으로 나뉩니다.
결론적으로 유사성이 높은 데이터들을 분류하여 군집을 만드는 분석 방법이기 때문에
관측값인 유사성을 잘 찾아야 하겠죠?
[ 종합 시나리오 #1 회귀분석 ]
- 선형 관계식 출력 및 평가
회귀분석을 시작하기 위해서 새로운 모델을 생성해주세요!
Load 함수를 통해 데이터를 불러올 건데,
데이터는 저번 포스팅에서 사용했던 setosa를 사용하겠습니다.
(Path 설정 및 Run 실행)
아까 회귀분석 설명에서 마지막 부분에서 언급한 테스트 기억나시나요?
선형 관계식을 테스트하기 위해서 함수를 추가하겠습니다.
Train Data와 Test Data로 나누기 위해 'Split Data'라는 함수를 추가해주세요~
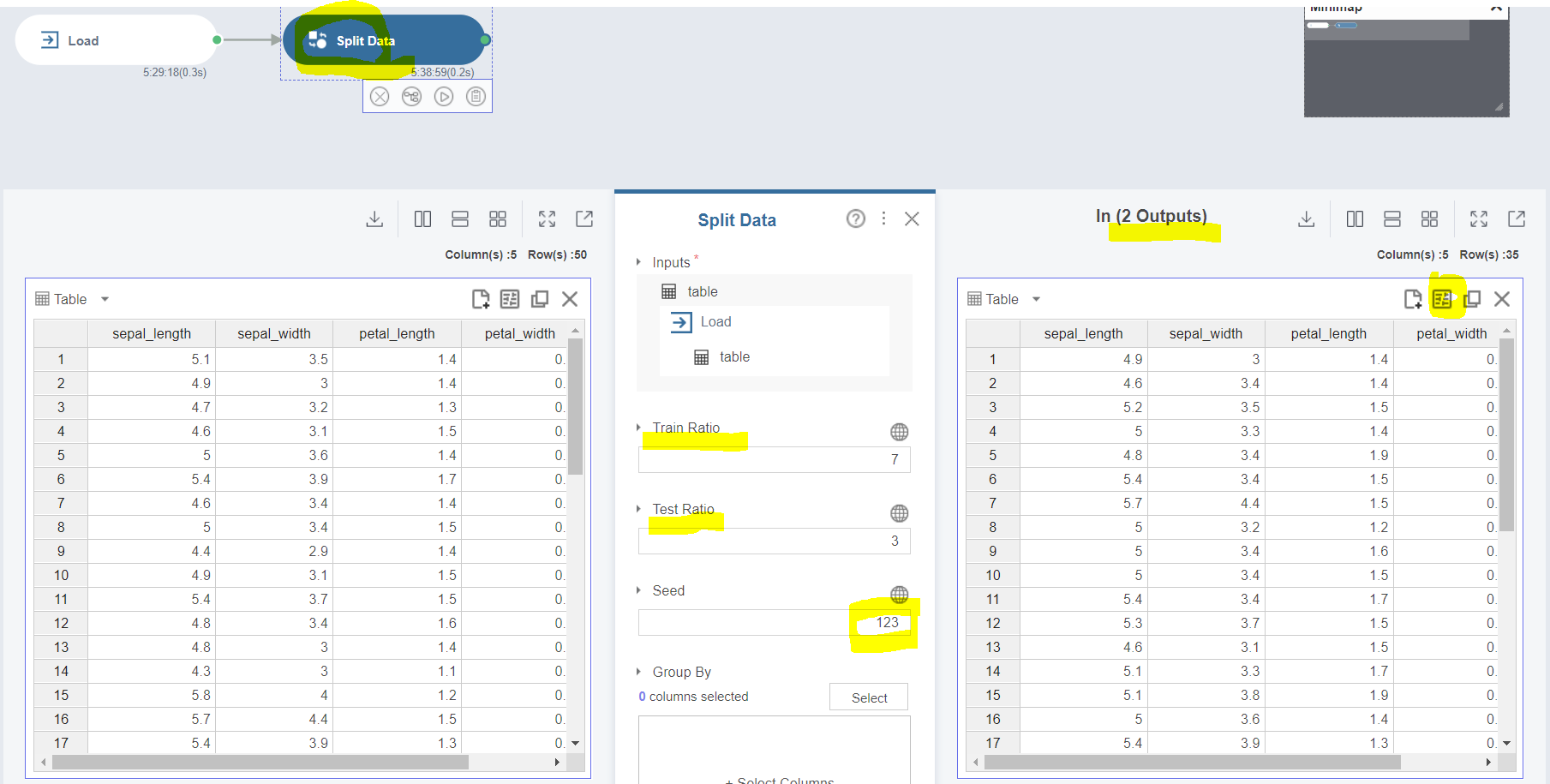
위와 같이 Split Data 함수를 추가한 후에
Train Ratio와 Test Ratio의 초기 설정값 그대로 설정해주세요.
Seed 값은 123으로 설정해주세요!
(데이터를 나누는 과정에서 랜덤 넘버로 나누기 때문에 넣어준답니다~)
Run을 누르면 오른쪽에 출력된 데이터를 확인할 수 있습니다.
'2 Outputs'이라고 쓰여 있는 이유는 말 그대로 출력 결과가 2개이기 때문인데요~
출력 결과 두 가지 모두를 보기 위해 Chart Setting을 해주겠습니다!
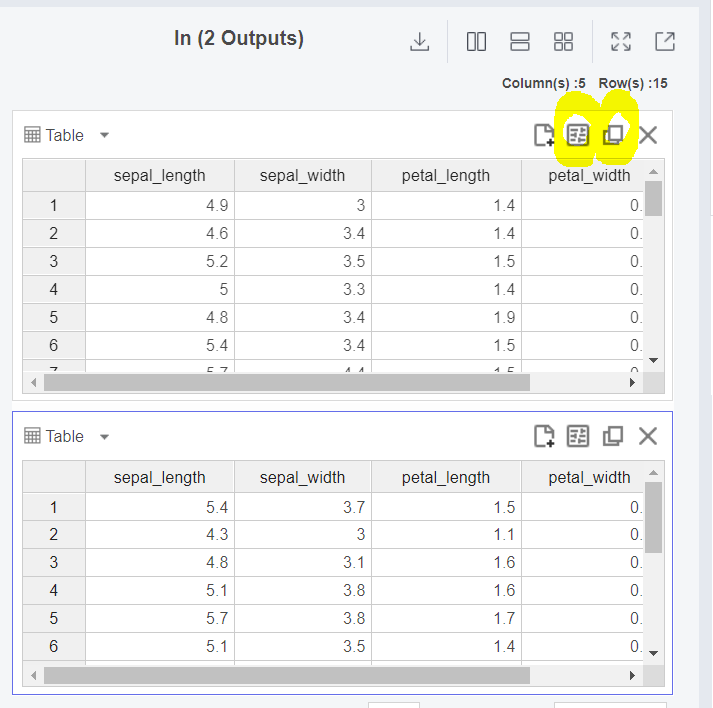
출력 창을 Duplicate를 통해 복사해준 후, Chart Setting으로 들어가 주세요!
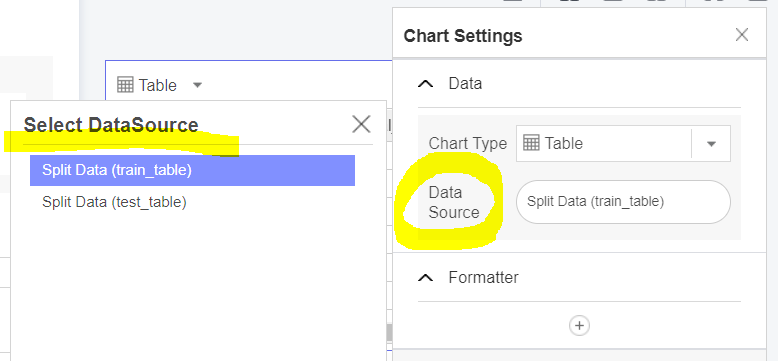
Data 탭에서 2가지 출력 데이터를 확인할 수 있는데,
두 출력 창에 각각 다른 Data Source를 설정해주면 됩니다.
이번에는 선형 회귀 분석을 위해서 'Linear Regression Train' 함수를 추가하겠습니다.
함수창 설정은 다음과 같이 해주세요!
1. Feature Columns : sepal_length
2. Label Column : sepal_width
3. Fit Intercept : True
(종속변수는 sepal_width, 독립변수는 sepal_length)
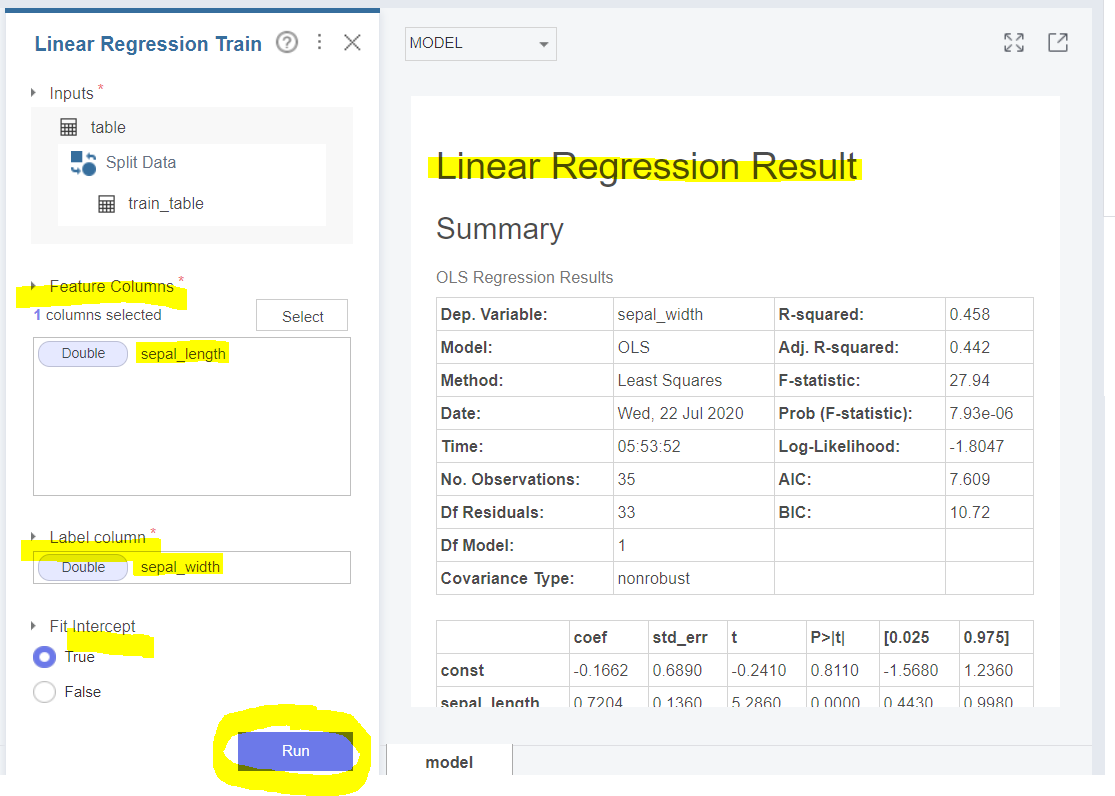
Run 하고 나면 오른쪽에 선형 회귀 결과가 나옵니다.
y절편 값은 -0.1662, 기울기는 0.7204 임을 확인할 수 있네요~
그렇다면 선형 관계식은
Y = - 0.1662 + 0.7204X
이렇게 표현되겠습니다.
이제 Test Data를 통해 Linear Regression Predict를 해보겠습니다!
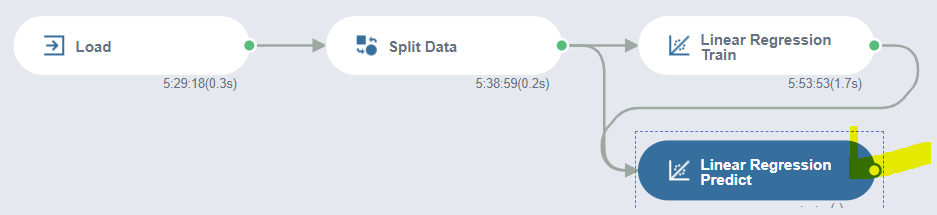
함수 'Linear Regression Predict'는 입력으로 테이블(Data)과 모델 모두 필요합니다.
모델은 이전의 Train 함수로 출력한 모델을 연결해주고,
데이터(테이블)는 이전의 Split Data를 통해 출력한 데이터 중 Test Table을 연결해주세요!
그냥 연결만 하면 디폴트 값으로 첫 번째 Data가 할당되기 때문에
잘 확인하고 틀리다면 Data를 변경해주어야 합니다.
(클릭해서 드래그로 변경 가능)
모든 함수와 동일하게 Run으로 데이터를 확인할 수 있습니다.
그다음으로 예측한 값을 평가해보겠습니다.
평가를 위해 'Evalutate Regression'이라는 함수를 사용하겠습니다.
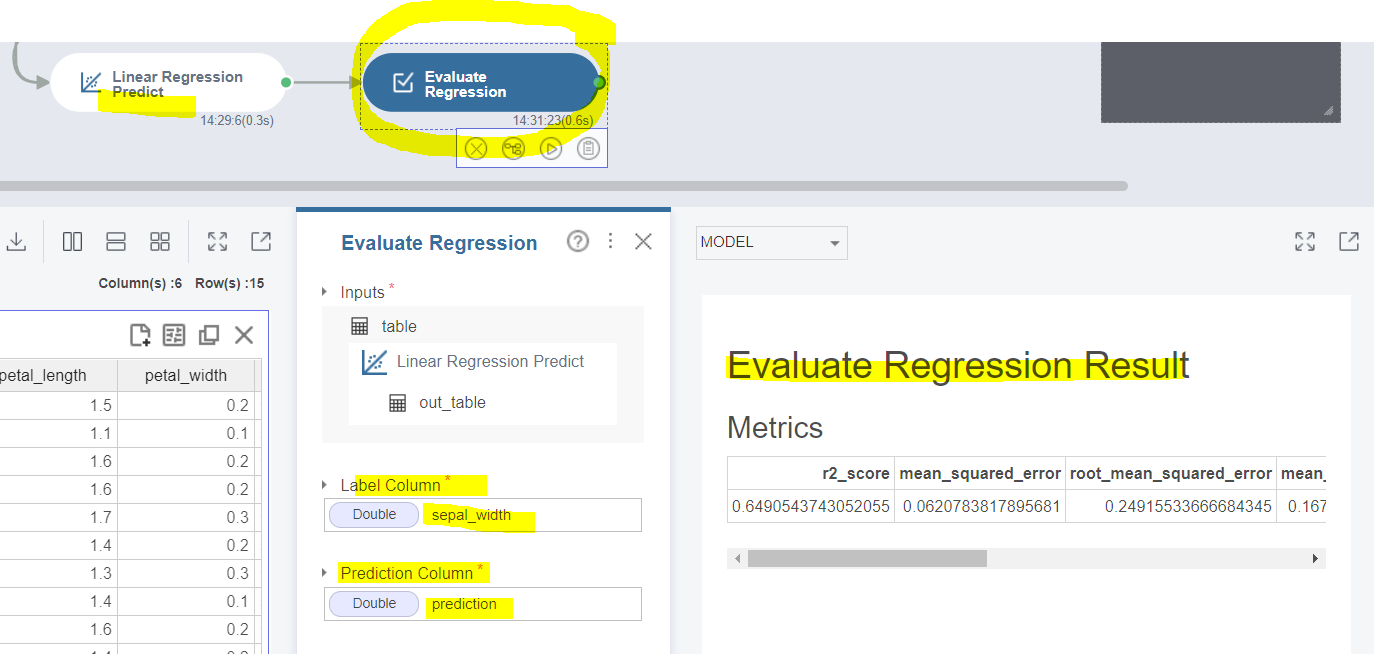
Label Column은 sepal_width, Prediction Column은 prediction으로
설정하고 Run을 누르면 오른쪽에 오차값 등의 평가값이 출력됩니다.
(참고로 Label Column은 정답, Predict Column은 예측값이라고 생각하면 됩니다.)
[ 종합 시나리오 #2 군집 분석 ]
- 데이터 군집 구별 (K-means Clustering)
시나리오 2번에서는 군집분석 실습을 진행하겠습니다.
1번과 동일하게 Load 함수를 사용하되, 이번에는 setosa가 아닌
원본 데이터 sample_iris를 이용하겠습니다.
그리고 군집분석을 위해서는 'k-means'라는 함수를 사용할 텐데,
이 함수는 유사한 값들을 묶어주는 군집분석 함수입니다.
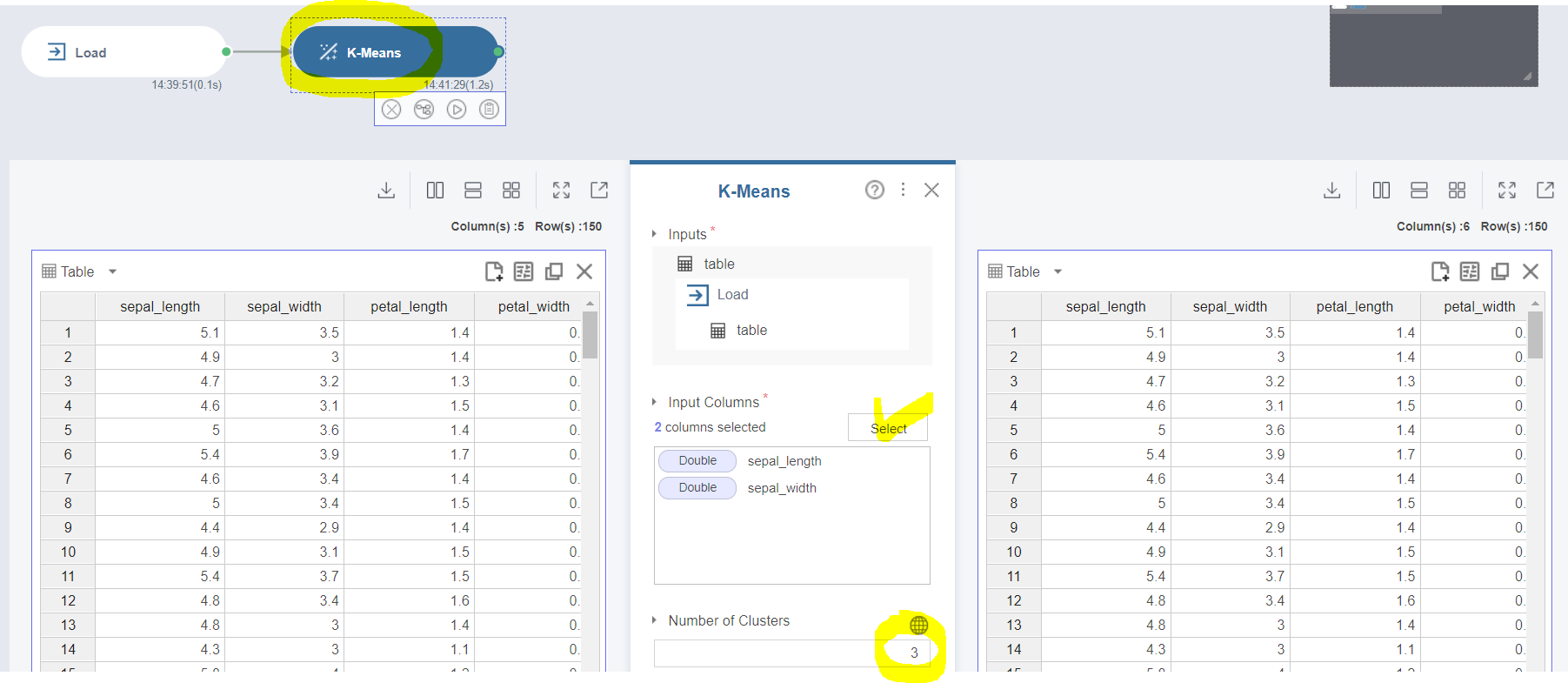
함수 창에서 입력 Column은 sepal_width, sepal_length를 선택하고
Number of Clusters, 군집 개수는 3으로 선택하겠습니다.
(iris 데이터의 경우, 종류가 세 가지이므로)
출력된 데이터를 확인해보면 predict가 0,1,2 중의 한 숫자가 지정된 것을 확인할 수 있습니다.
species에 따른 그래프와 predict값에 따른 그래프를 비교해볼까요?
Scatter Plot으로 비교하겠습니다.
Duplicate로 두 가지 그래프를 만들고, Color By는 각각 다르게 설정하면 됩니다.
하나는 species, 다른 하나는 predict로 설정해주세요!
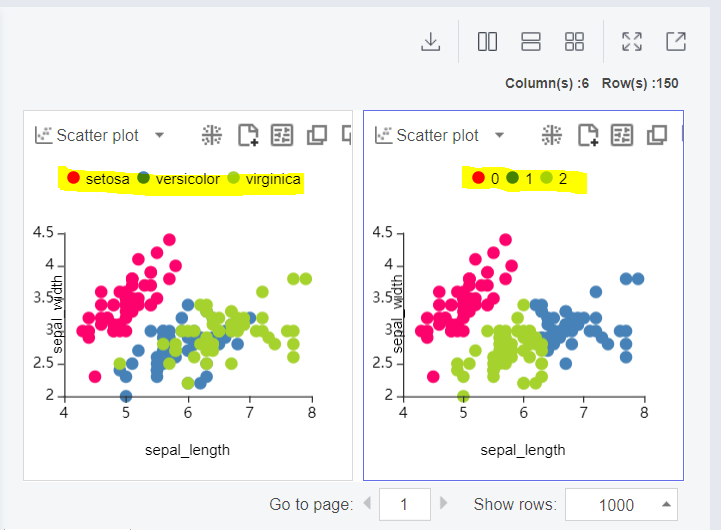
왼쪽은 species에 따른, 오른쪽은 prediect에 따른 그래프입니다.
그래프를 잘 살펴보면 모양이 다른 것을 한눈에 알 수 있습니다.
왼쪽과 달리 오른쪽은 versicolor와 vriginica가 거의 겹치지 않았음을 알 수 있죠?
(예측하건대 versicolor는 초록색인 2번으로, virginica는 파란색인 1번으로 구분된 것 같습니다.)
이렇게 분류된 군집분석 데이터를 평가하겠습니다!
평가를 위해 함수 'Evaluate Classification'을 사용하겠습니다.
입력으로 Label Column은 species, Prediction Column은 Prediction으로 설정할 건데,
문제는 Run을 눌러도 실행이 되지 않고 에러가 발생합니다.
이유는 두 input의 데이터 형태가 다르기 때문입니다.
species는 string, Prediciton은 integer이기 때문이죠!
별도의 작업을 통해 코드를 맞춰줘야 에러가 나지 않고 실행 가능합니다!

우선 K-means와 Evaluate Classification을 떨어트리고 함수 연결을 끊어주세요!
그런 다음 'Add Column'이라는 함수를 통해서 코드를 맞춰주겠습니다.
저 사이에 Add Column 함수를 추가하고 함수 창에서 Add Column을 클릭해주세요!
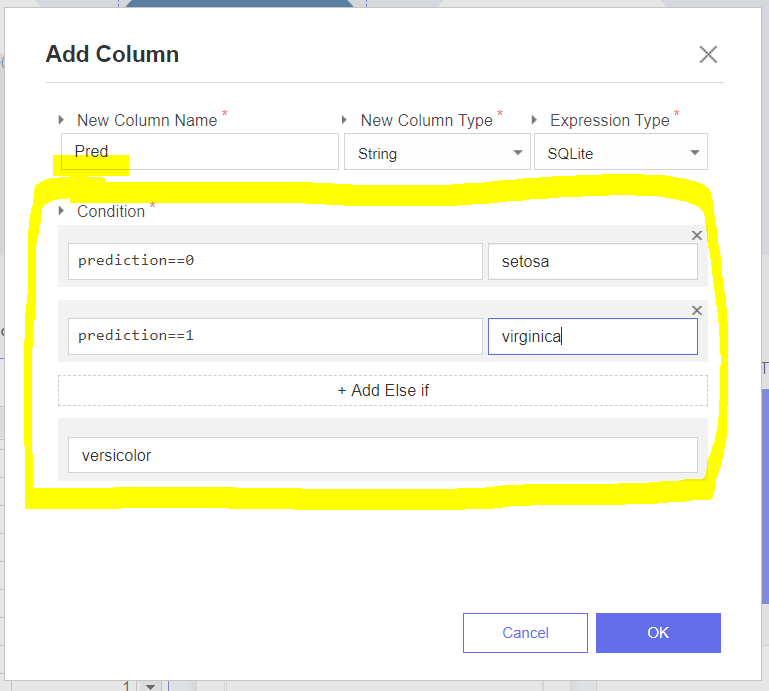
여기서 새로운 Column의 이름은 임의로 설정해주시면 되고,
아래의 Condition은 species에 따라서 숫자를 설정해주겠습니다.
Condition은 Else if 문을 여러 가지 추가 가능합니다.
잘 모르시는 분들을 위해 설명드리자면
조건문, if 문은 조건을 만족하는 경우에 지정한 행동을 수행하는 함수입니다.
if, else if, else로 나뉠 수 있는데,
조건이 있는 if는 가장 첫 번째 조건문일 경우, 그 외의 조건문은 else if로 설정할 수 있고
else는 그 외의 나머지 모두를 의미합니다.
조건문처럼 왼쪽에는 조건을, 오른쪽에는 조건을 만족할 경우에 입력한 데이터 값을 설정해주고
0번과 1번을 설정해주었으니 당연히 마지막 else에서는 2번만이 남으니
마지막은 versicolor로 설정해주면 됩니다.
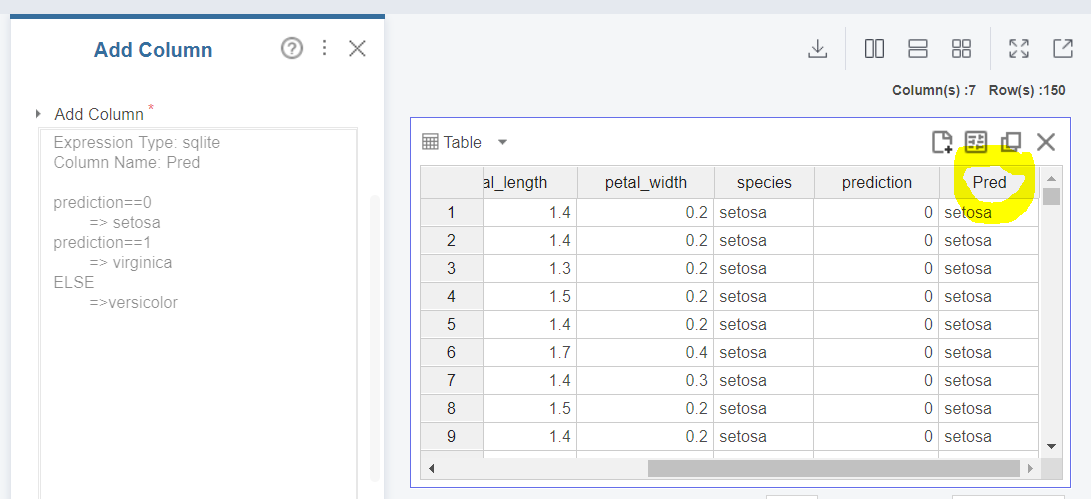
Run으로 실행해주고 나면 이렇게 데이터에 Pred라는 Column이 추가된 것을 확인할 수 있습니다!
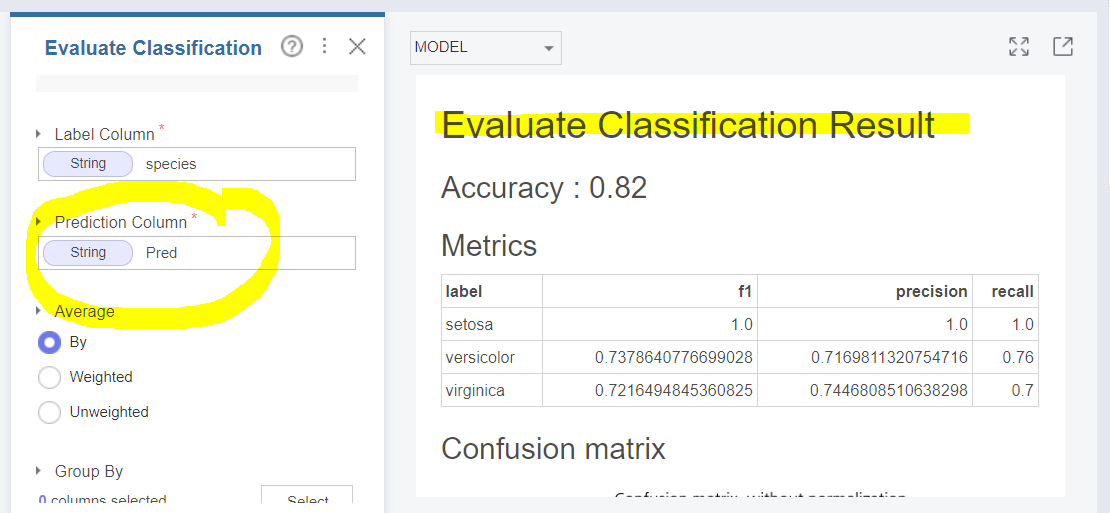
데이터 형태를 변환해주었으니 Prediction Column을 Pred로 바꾸어주세요!
그럼 다음과 같이 에러 없이 실행이 되는 것을 볼 수 있을 거예요!
평가값에서는 Recall, Precision, F-score 값들과 Confusion matrix를 확인할 수 있습니다.
끄읏-!
이번 포스팅에서는 종합 시나리오를 통해서
이전에 설명했던 사용 방법을 리뷰하고,
선형 회귀분석, 군집 분석 실습을 진행했습니다.
회귀분석과 군집분석에 대해서 잘 모르시겠다면,
나중에 자세한 포스팅을 설명해드리겠습니다!
데이터를 분석하는 과정은 분석에 대한 지식을 요구하고,
그 과정 또한 해당 프로그램에 대한 지식이 없으면 힘든 것 같습니다..
하지만 그것만큼이나 중요한 것이 있죠..!
바로 리포트 작성입니다!
데이터를 분석했는데 분석한 것을 토대로
report를 제대로 작성하지 못한다면 소용없겠죠?
그래서 다음 포스팅에서는 Report 작성을 실습해보겠습니다!
포스팅에서 오류나 오타를 발견하셨다면
댓글로 피드백을 남겨주세요~ :)
그럼 다음 포스팅에서 만나요~
٩( ᐛ )و
* Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다. *



